TL;DR:Observability can be applied to front end code, specifically: user events, HTTP events and browser events. Tracing can reveal all the events in a particular user-system interaction, while querying across events can identify patterns and anomalies or just learn more about how the system functions. Observability can be surfaced in documentation, empowering all members of a multi-disciplinary team.
I've been reading the book Observability Engineering by Charity Majors and thinking about how to apply the ideas to front end development.
She describes the concept of a structured event - an event "which captures everything that occurred while one particular request interacted with your service" (Chapter 5).
On the front end, a structured event might capture everything that happened during, say, a user interaction or receipt of an HTTP response. This might be done by placing logging calls at key points in the code, similar to how we might place console.log statements for local debugging.
In this article I'll give an overview of front-end observability with some examples using Sentry.
Observability on the front end#
A key benefit of structured events (compared to unstructured logs) is that they can contain rich contextual data points:
- User events, such as what value was entered into an input
- HTTP events, such as responses received from a backend
- Browser events, such as location data

These data points are queryable and we can filter for them using the powerful querying facilities of a monitoring platform such as Sentry, DynaTrace, AWS CloudWatch RUM or Azure Monitor.

With structured logs in place, developers can "ask" arbitrary questions about how the application is behaving in production.
We can pro-actively search for unanticipated bugs or diagnose difficult errors involving complex front end logic.
Let's look at some examples.
Example 1 - User event#

Suppose our front end app validates a change to a numeric field:
When the user edits the stake of a shareholder, we want to validate that the total of all shareholder stakes is never more than 100%. But this only applies to active shareholders – we want to skip shareholders which have been turned off.
We want to make the state of our component observable.
Let's log two structured events:
- changeStakeValid - stake was valid; we'll submit a PATCH
- changeStakeSumError - stakes sum was too high; we'll show an error
const handleClickSave = async (e) => {
if (othersAndThisStakesSum <= 100) {
captureEvent({
message: "useShareholderStakeEditor/changeStakeValid",
tags: event.tags,
contexts: {
["useShareholderStakeEditor/changeStakeValid"]: event.data,
},
});
await patchShareholderStake({
id: shareholder.id,
stake,
});
refreshShareholders();
} else {
captureEvent({
message: "useShareholderStakeEditor/changeStakeSumError",
tags: event.tags,
contexts: {
["useShareholderStakeEditor/changeStakeSumError"]: event.data,
},
});
showShareholderStakeError();
}
}Suppose we subsequently receive a bug report:
The user attempted to enter a 20% stake for one node, but got an error, despite the enabled nodes having a total <= 80%.
We might ask ourselves a bunch of questions:
- Why didn't our "enabled" logic work in this case?
- Was there a bug in the front end logic?
- If so, how should we fix it?
Instead of having to guess or consult various sources, wouldn't it be nice if we could more directly observe what happened?
Let's query Sentry for:
- Events generated by this component -
message:"useShareholderStakeEditor*" - For this user -
user.id:1234 - And this company -
companyId:5678
We find our error event - changeStakeSumError:

Clicking on the row reveals some interesting details:
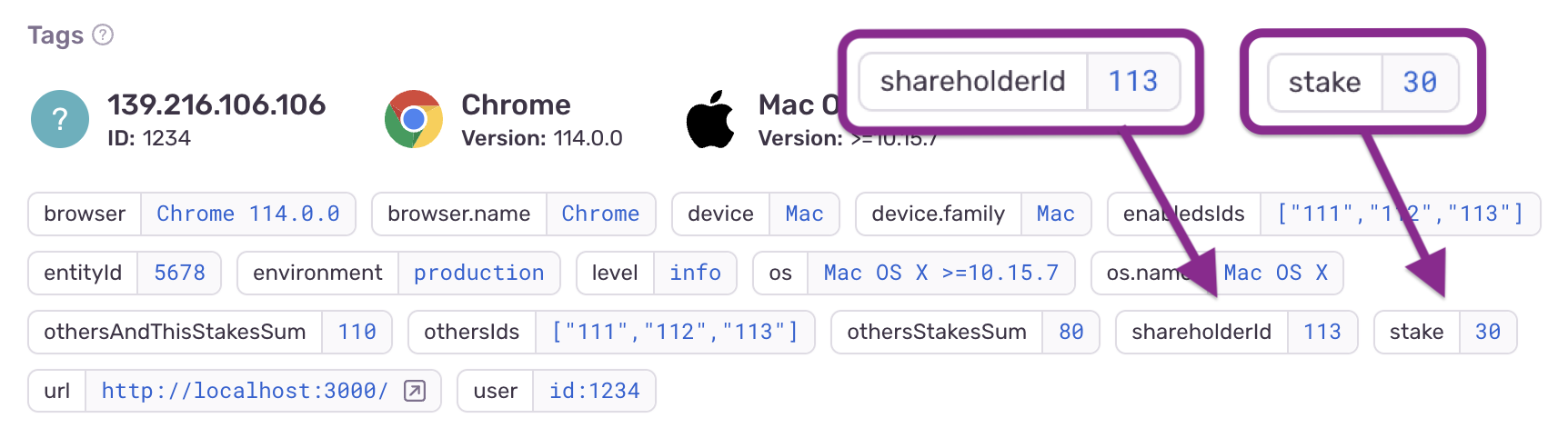
![Sentry error details, showing an item (id: 112) with the word "[Deleted]" in its name](/images/articles/front-end-observability/example-stake-sentry-query-result-detail.png)
We see that the user was trying to set one shareholder (id: 113) to have a stake of 30%.
However, another shareholder (id: 112), which was enabled: true, had the word "Deleted" in its name. The presence of the word "Deleted" likely confused the user into thinking that its 40% stake would not included in the total.
Now we have enough information to propose further actions:
- Solution: We could add logic that removes words like "Deleted" from names of shareholders, to avoid confusing the user like this in future
- Solution: We could ask the user to disregard words like "Deleted" and share that knowledge with other users publicly (e.g. via Slack)
- Investigation: We could find out why users were using the word "Deleted" in shareholder names; is the delete function broken?
Notice that we don't have to ask the user questions and wait for their response, nor run the application and attempt to reproduce the error, nor query the database, nor puzzle over server-side logs.
Rather, we can to go directly to the root of the problem, observing logs generated by the specific part of the code which the user was interacting with at the time of the event.
Even better, by naming each logging statement uniquely and using a strict hierarchical naming convention (e.g. ${component}/${event}), we can query more broadly by component, then narrow in on the event, to locate the exact line of code which generated the event!
When you think about it, observability is not all that different from the standard practice of adding console.log statements at appropriate points and debugging locally – only it's more rigorous and queryable and we can observe production.
Example 2 - HTTP event#

On saving a shareholder's stake, the front end app should refresh the list of all shareholders' stakes.
But suppose we receive another bug report:
A user reports that the stakes did not refresh after they saved a stake.
So we ask some questions:
- Why did the refresh not work?
- Was there a problem with the PATCH request?
- Did the front end code handling of the PATCH request fail?
- Was there some other kind of issue?
If we log an event on refresh, it should be easier to find out.
function ShareholderValueEditor({ companyId, shareholder }) {
...
const handleClickSave = async (e) => {
if (othersAndThisStakesSum <= 100) {
...
const patchStakeResult = await patchShareholderStake({
id: shareholder.id,
stake,
});
captureEvent({
message: "useShareholderStakeEditor/changeStakePatchCompleted",
tags: event.tags,
contexts: {
["useShareholderStakeEditor/changeStakePatchCompleted"]: {
...event.data,
patchStakeResult,
},
},
});
const refetchShareholdersResult = await refetchShareholders();
captureEvent({
message: "useShareholderStakeEditor/changeStakeRefreshCompleted",
tags: event.tags,
contexts: {
["useShareholderStakeEditor/changeStakeRefreshCompleted"]: {
...event.data,
refetchShareholdersResult,
},
},
});
} else {
...
}
}
...
}As in the previous example, let's query Sentry for:
- Events generated by this component -
message:"useShareholderStakeEditor*" - For this user -
user.id:1234 - And this company -
companyId:5678
We find our two events - changeStakePatchCompleted and changeStakeRefreshCompleted - were both logged:
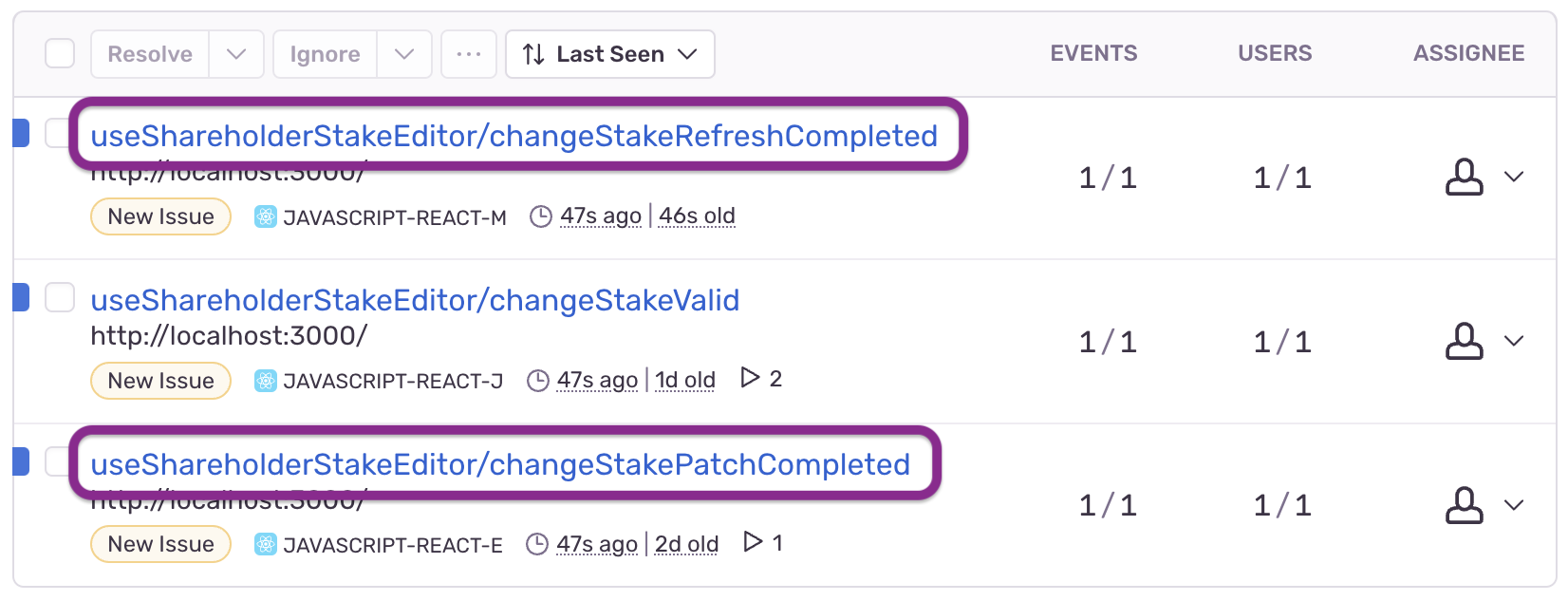
However, examining the refresh event, we see that the new stake value was not provided.
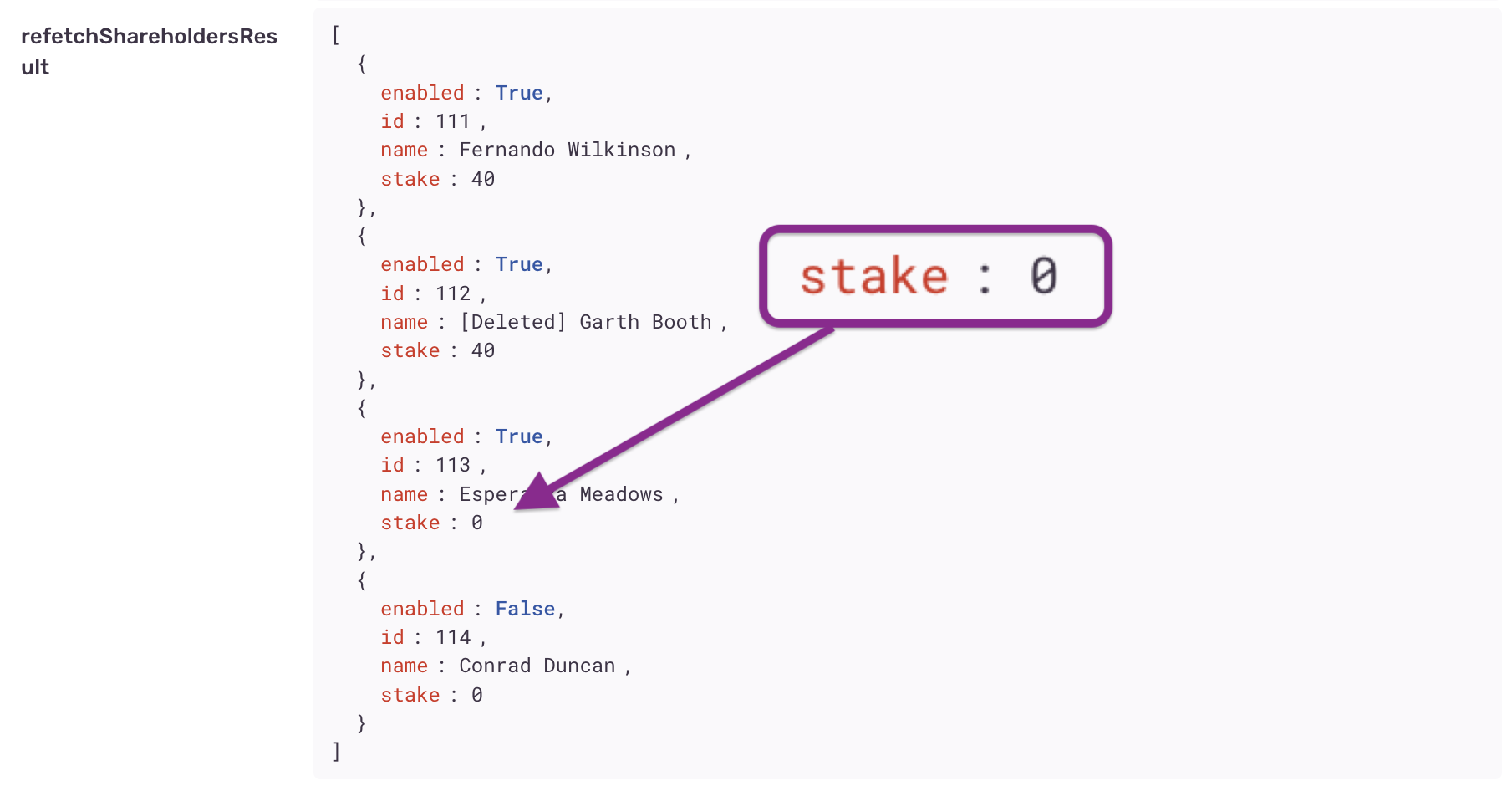
Now we know why the stake did not refresh properly – the back end is returning stale data! We'll need to discuss cache-busting with the back end developers.
Example 3 - Browser event#

For our final example, suppose the front end app should refresh the list of all shareholders' stakes periodically, e.g. every 30 seconds.
We receive the following bug report:
A user reports after one user had modified the stakes of certain shareholders, the other users didn't see the updates until the following day.
We might ask:
- Why did the auto refresh not work?
- Was there a problem with the GET request or code handling the response?
- Was there a Backend issue, such as a cache becoming stale?
Let's query Sentry for observability on the auto-refresh hook:
- Events generated by the hook -
message:"useShareholdersAutoRefresh*" - For this company -
companyId:5678
We find our autorefresh event - useShareholdersAutoRefresh - was logged:

And hovering over the events column, it looks like it has been running at regular intervals:
What could have gone wrong? Inspecting the details, we see that different values were returned for one user than for another:
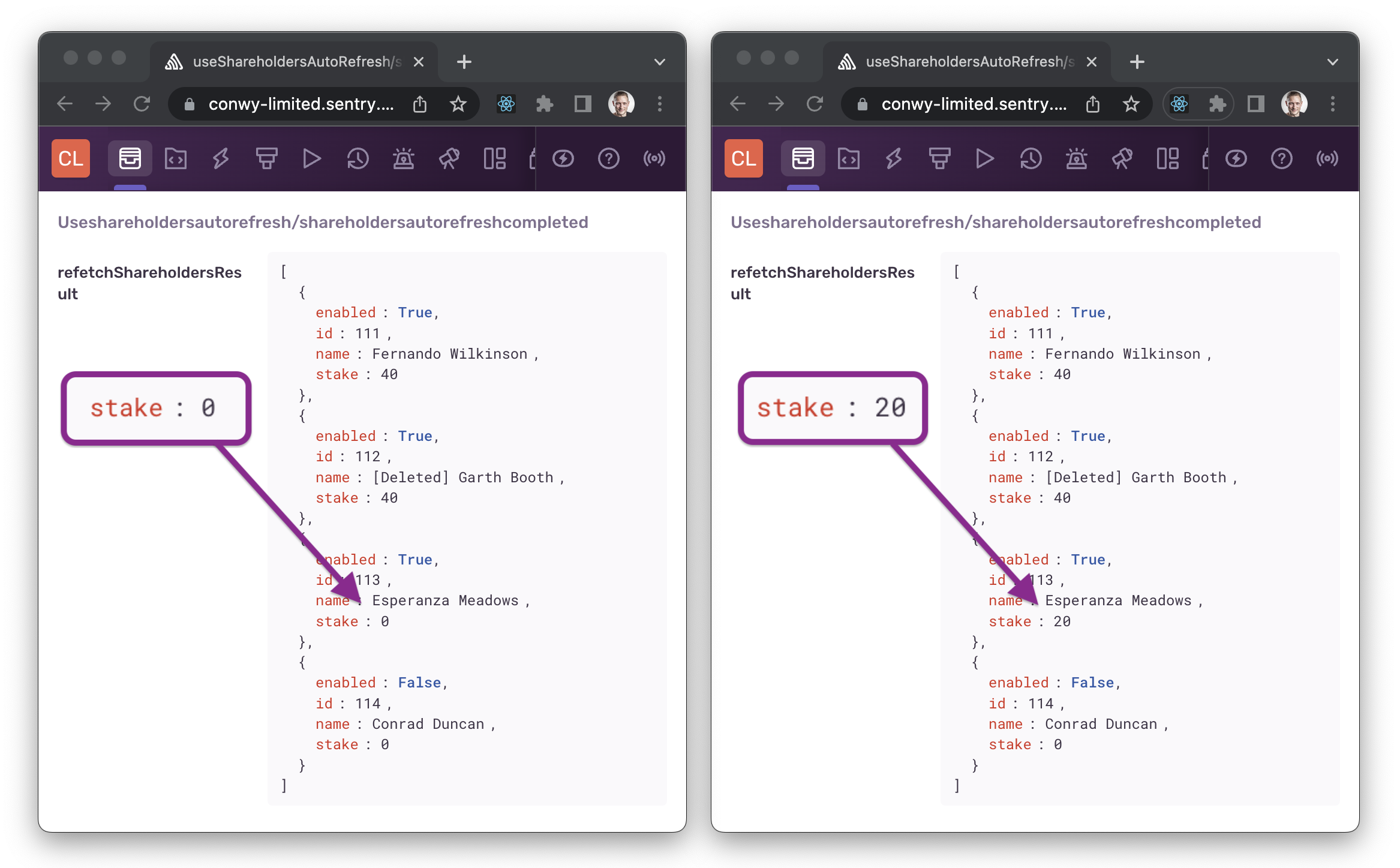
This indicates that the back end may be serving stale updates for some users, rather than propagating changes to all users at once.
Tracing with breadcrumbs#
From the previous examples, you may have noticed continuity between events. For example, the user action of editing a shareholder stake generates a sequence of related events: changeStakeValid, changeStakePatchCompleted, changeStakeRefreshCompleted.
Wouldn't it be nice if we could see a sequence or "flow" of events together in a list?
Thanks to Sentry's breadcrumbs feature, we can. Simply open the details of one of the events, scroll down to the Breadcrumbs section, then filter by "Tranaction".
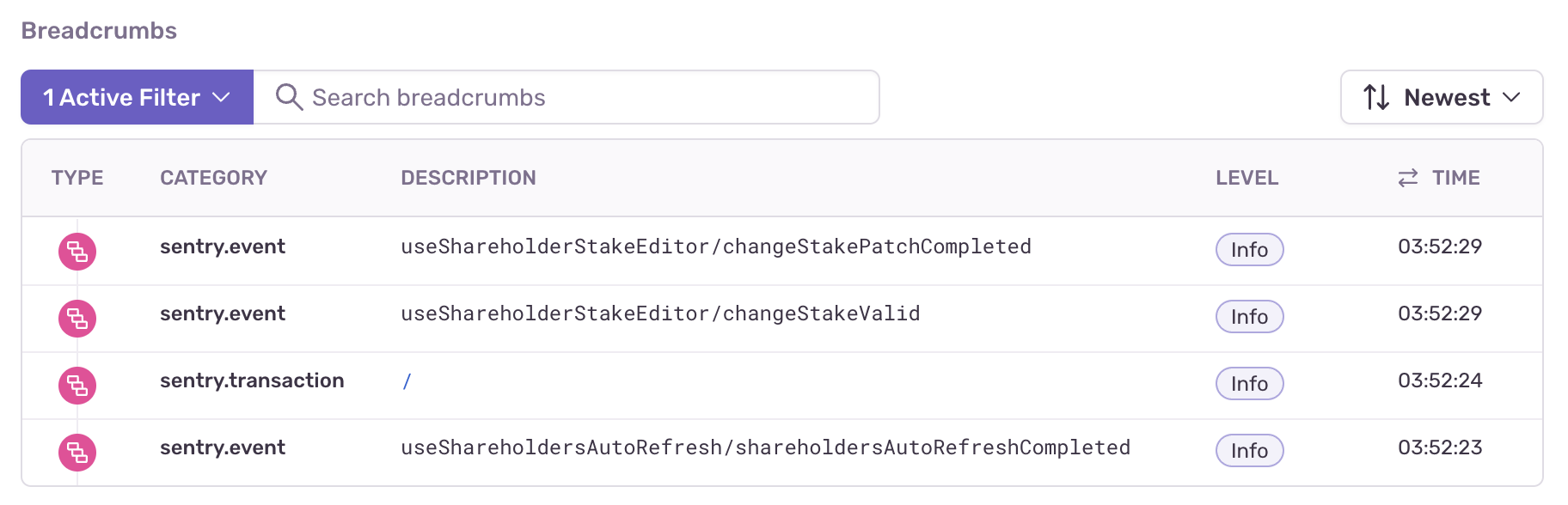
Querying across events#
With detailed structured events in place, we can form more interesting queries, proactively searching for anomalies or just simply learning more about how our system functions in production.
For example, as we included companyId in the events concerned with shareholders, we could more generally query all events associated with that companyId. More powerfully, we could query all events associated with any companyId, that is, all company-related events. This could be useful if company was an important entity in our system and we wanted to prioritise fixing of errors related to that entity.
Or take another example – querying by date and time. We could query for events with message:"*error*", within a time of day in which users are experiencing a lot of issues. This would allow us to diagnose the cause of those issues separately from more time-independent issues.
Observability and documentation#
Documentation can be an excellent place to surface observability.
Links to queries in a monitoring system can be placed in wiki pages, where they can be discovered by our team members or others in the organisation as needed.
For example, from our previous example, wouldn't it be great if a new team member could not only read a textual description of Shareholder stakes, but also be linked to actual production data around this feature?
We could achieve this by querying Sentry for all events with message:"*shareholderStake*", grabbing a link to that query and pasting it into a "Shareholder stakes" wiki page, perhaps under a heading titled "Observability" with a link titled "shareholderStake events".

Imagine if all feature documentation was augmented with links to observability queries. This could give newcomers and experienced team members alike a boost in understanding how each of those features functions in production.
Managing observability code#
In the interests of keeping code clean and readable, we might want to reduce the quantity and complexity of logging code.
Some ideas:
- Abstraction
- Removal
- Aspects
Abstraction
We can hide logging behind a more abstract function, to reduce its complexity and surface area.
For example, in a React codebase, rather than directly calling captureEvent from @sentry/react, we could create and consume our own custom hook, named something like useLogEvent returning a function like logEvent. The hook and function could encapsulate concerns such as caching re-used data and following a hierarchical naming convention.
Removal
Similar to feature flag controls, logging code could be scheduled for removal after a period of time, if the software has been working well and is considered not in need of monitoring.
Alternately, we could comment-out logging calls or add a special flag to disable them. Developers could quickly determine that the code is not in use and skip over it.
Aspects
Aspect-oriented programming involves augmenting the behaviour of existing code without modifying it, typically using a declarative pattern such as decorator. Frameworks such as AspectJ are already used for logging in back end systems.
In front end, Typescript Decorators may in the near future allow logging to be added in a similar, unobtrusive style.
Security and privacy#
A word about security – sensitive data (such as personal data) should probably be omitted from structured events, to avoid data leakage and comply with regulations.
The chance of sensitive data being accidentally leaked grows with increased use of logging in production (as with any other use of data production). So if your system deals with sensitive data, it's crucial to have processes in place to ensure that this data is not leaked in logs. This could be part of a code review process as well as an ongoing independent review process, likely involving examination of both code and logs.
Conclusion#
Observability in software engineering is about observing the internal state of a software system during regular usage in production, typically by capturing and monitoring detailed and structured log outputs.
While more commonly applied to distributed systems on the back end, observability can also be applied to the front end, using front end compatible tools such as Sentry to observe states generated by user, HTTP or browser events.
Distinct from typical logging, structured events capture detailed contextual information surrounding the events and make the events queryable (e.g. with tags in Sentry) and traceable (e.g. with Breadcrumbs in Sentry).
Using structured data generated by production logging, we can diagnose an issue or answer an unanticipated question about the behaviour of the system. Additionally, we can proactively search for issues or anomalies by querying across events. And those queries can be integrated into documentation, where they can be discovered and accessed by engineers or other interested parties.
Observability is a newly emerging field within software engineering, and we can't know for sure what it will look like in the future. Increasing the observability of a front end could potentially be a very worthwhile pursuit, in terms of time and cost saved, where an application is already running in production and complex issues need to be diagnosed and resolved quickly.
Code example#
The source code for the examples mentioned in this article can be found here:
https://github.com/jonathanconway/observability-example-react
Further reading#
These resources inspired this article:
- Observability Engineering by Charity Majors
- Sentry Browser JavaScript Docs by Sentry
