

Recent experiments with mock data reveal a surprisingly versatile tool that can boost developer productivity and enjoyment.
Mock data, dummy data, fake data, test data, sample data.
These terms all express the same thing:
Data that a developer hard-codes in place of real data.
In my observation, mock data has tended to be used in a rather loose, slipshod, careless manner. Unlike documentation, it is treated as the garbage of software material. (Sometimes even referred to as "garbage data"). People will try to avoid writing it by using elaborate "generators" such as jFairy or zed.
My argument in this article is that mock data, when treated with respect, turns out to be a supremely useful, versatile and valuable tool.
I find four special uses for mock data:
- Iteratively designing and documenting structures
- Boosting unit test development
- Manually testing a running application
- Decoupling development teams
In this article I will elaborate on each of these uses.
1. Iteratively designing and documenting structures
Let's begin with an example that should be reasonably familiar to most developers:
Validating a username in a sign-up form.
Suppose we want to capture and validate one of three kinds of username:
- an email address -or-
- a 9-character alpha string -or-
- a numeric employee number
We might begin by modelling the username field as a string | number data-type that covers all three kinds of username.
type Username = string | number;
The above type expresses a part of our requirements but not all of them. Specifically, it doesn't express such facts as:
- the username might be an email
- the username might be a 9-character string
- the username might be a string longer than 9 characters, but that would be invalid
How might we express these requirements in code prior to writing a validation routine?
One way might be to write descriptive comments next to the field. Another way might be to bring in a hefty and cumbersome "validation framework" such as zed and try to twist and wrangle it to the shape of our specific requirements.
Or... we could simply create a few mock values:
const UsernameMocks = {
EMAIL: "user@website.com",
TEXT_NINE_CHARS: "ninechars",
TEXT_LONGER_THAN_NINE_CHARS: "longerthanninechars",
NUMBER: 1234,
};
We have now enumerated the variants of the username field that we expect to deal with.
And we've given them descriptive names. Naming them this way helps us to think clearly about the requirement and allows us to document the requirement in code.
Looking at these mock values, we might also begin to ask questions. For example: does a numeric username have a lower and upper bound? Safe assumptions might be 0 and Number.MAX_SAFE_INTEGER, but we might want to check with a domain expert.
The point is, by laying out all the expected values of this field together in one view, we give ourselves an opportunity to think more deeply about the range of possible cases and how we will deal with these cases. In this way, mock data becomes a kind of tool for concretising requirements.
We can now begin to think about how we might design and test the validation routine.
2. Boosting unit test development
As we begin to write a username validation function, the Username type definition combined with UsernameMocks given above lead directly to four unit tests:
describe("validateUsername", () => {
it("validates email as true", () => {});
it("validates text 9 chars long as true", () => {});
it("validates text more than 9 chars long as false", () => {});
it("validates number as true", () => {});
});
This isn't a coincidence – the whole point of mock data is to represent kinds of values we expect to deal with. Our unit tests need to do the same thing, to verify that the system under test behaves as we expect.
We can now begin to implement the requirement, writing each of the unit tests one by one, and writing enough code to make it pass.
Alternately / additionally, we could use this information about expected inputs to scaffold the function with comments:
function validateUsername(username: Username): boolean {
// If email, return true
// If number, return true
// If less than or equal to 9 chars, return true
// Return false
}
This is just scratching the surface!
As we write the tests, we notice that we can reference the mock constants directly inside the test code, to avoid repeating ourselves.
For example:
describe("validate username", () => {
it("returns true for email address", () => {
const output = validateUsername(UsernameMocks.EMAIL);
expect(output).toBeTruthy();
});
});
Notice how clean and readable this test is! The naming of the mock constant reveals the intent of the test beautifully. Rather than pollute our test code with concrete values, we can extract them to well-named constants and have the test code focus on the relationships between the values.
The re-use can go even further. Suppose, in a different part of the code, we want to display a user profile which includes the user's username. We want to style the text differently depending on what kind of username the user has.
We might extract the username type and mocks to its own module, say, username.ts. Then we can re-use the mock usernames in our tests, like so:
describe("user profile", () => {
it("renders number username in monospace", () => {
const usernameEl = renderUsername(UsernameMocks.NUMBER);
expect(usernameEl).toHaveClass("mono");
});
it("renders email username in sans-serif", () => {
const usernameEl = renderUsername(UsernameMocks.EMAIL);
expect(usernameEl).toHaveClass("sans-serif");
});
it("renders alpha username in sans-serif", () => {
const usernameEl = renderUsername(UsernameMocks.TEXT_NINE_CHARS);
expect(usernameEl).toHaveClass("sans-serif");
});
});
In future we might need to maintain username code – e.g. support additional kinds of username, remove support for a kind of username, fix a mistake in one of the mock values, etc.
It will be much easier to find the code that needs to change across the whole codebase if we use consistent mock constants than it will be if we use inconsistent mock literals.
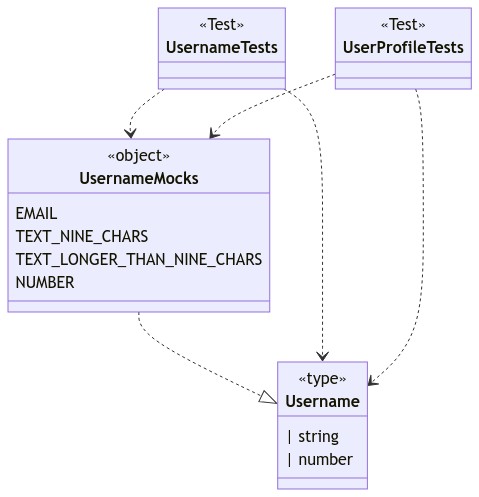
The end result is that any test code that deals with mock values will be:
- faster to write
- easier to read
- more maintainable
Bonus: And we're talking about more than just unit-tests here! Mock values can also be used to fill in live component demos (e.g. Storybook stories), dynamic documentation (e.g. Docusaurus pages) and snapshot tests (e.g. PhantomJS screenshots).
3. Manually testing a running application
Imagine if our application was augmented with mock data in such a way that all of its features could be used while running purely off the mock data, without ever having to connect to any real data-source. (By 'data-source', I'm referring to things like databases, APIs, etc.)
This capability would offer some unique advantages:
- We could simulate any behavior we desired in our application (by mocking states that could trigger that behavior)
- We could test how the application would respond to an unexpected state (by mocking that state)
- We could run and develop the application entirely on mocks while the external data-source was down, e.g. during an outage or planned maintenance
- We could develop new features in advance of the data-source supporting them (adding mock data as needed and only substituting real data as it becomes available)
- We could demo features of an application to stakeholders prior to having an external data-source to support that feature
- We could mock data to model changes to an external data-source, to clarify our own thinking and/or to communicate requirements to the data-source maintainers
Mocking all of an application's data-sources might seem like a daunting task. However, in my experience, it's easier than it might seem, especially if done in the early stages of a project.
But there are a few pre-requisites.
Firstly, the application needs an interchangeable data-source, so we can switch between real data and mock data. We need to write all our application code against that data-source abstraction, without concern for where the data actually comes from.
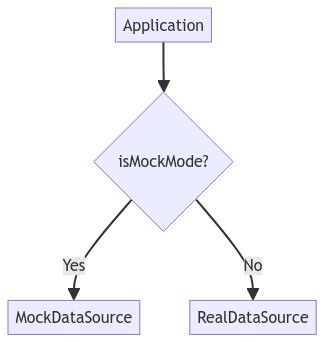
Secondly, we need to be able to switch the Application state between the real data-source and a mock data-source.
-
Some Single Page Application (SPA) projects use a state container such as Redux. In that case, we might dispatch a
SetMockStateActionwhich sets anisMockModeflag in the store. When this flag istrue, all data-retrieval actions use mock data rather than making a real HTTP call. -
In other cases (typically a SPA or a micro-service), an HTTP API client sits between the Application state and the HTTP API and calls the HTTP API to fetch data. We could add a
setMockStatemethod here, which sets a privateisMockModefield which, whentrue, uses mock data rather than making a real HTTP call. Or we could set up a Dependency Injection (DI) system, in which an abstractAPIClientinterface is implemented byHttpAPIClientandMockAPIClient, which can be substituted at runtime.
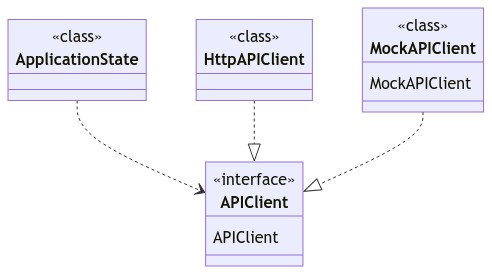
The "switch" could be activated by clicking a UI element, e.g. a small checkbox in the footer area of a web page, which is only visible to Admin users. The click handler toggles the Application state between real data-source vs. mocks.

Thirdly, we need all of our application state to be mocked in a set of mock constants. This is easiest if the application state is modelled in some more abstract way, e.g. using classes, interfaces, types, etc. That way, we can easily construct our mock data as a realisation of those abstractions.
It would take significant effort to completely mock the data-sources of a pre-existing application. But that effort could be broken down into smaller pieces and pursued incrementally, similar to adding unit tests.
Once our application is completely augmented with mock data, maintaining the mock data going forward would only add a small overhead (and might even boost development speed, as described in sections 1 and 2).
How about switching between multiple mock states? One way would be via a collection of mock controls, presented to Admin users in the UI, allowing the mocks to be adjusted at whatever level of detail is needed. These could be presented in a pop-up modal or panel activated by clicking a Mock Settings button located somewhere out-of-the-way and only accessible to Admin users.
The following screenshot depicts mock controls for a hypothetical online banking application, allowing the user's home country, preferred currency and business / personal accounts to be adjusted.

4. Decoupling development teams
Once our entire Application is able to run off mocked data, not only can we operate the application while a data-source is unavailable, but we can also operate and develop application features prior to the data-source even supporting them.
Mocking our data-sources decouples our team's development efforts from other teams.
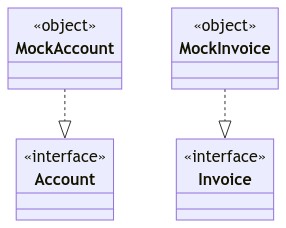
For example, imagine we are working in an Invoicing team in an online banking system. We want to build a "Foreign Accounts" feature. Suppose this feature depends on data from an Accounts team. Without mock data, the Invoicing team might have had to await until the Accounts team had built certain APIs, which it would then consume.
But with mock data, the Invoicing team no longer needs to wait for the Accounts team to support a Foreign Accounts feature, but rather, it can immediately begin developing the Foreign Accounts feature. We merely need to model Foreign Accounts interface in a way that makes sense for Invoicing purposes, and from those models, derive mocks.
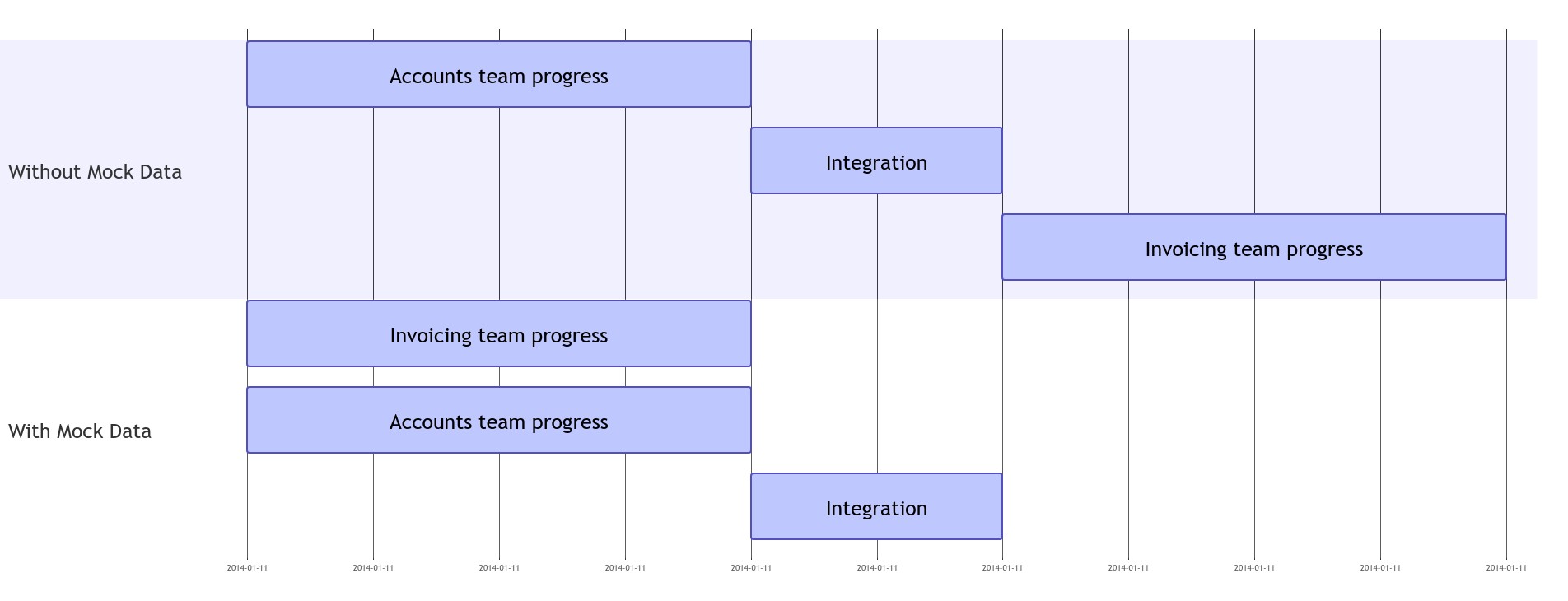
We can develop and test all the Invoicing logic against those mocks. When the Accounts team does finally support Foreign Accounts we can connect our Invoices system to theirs. Any dissonance between their models and ours can be solved by adding a mapping layer, e.g. an AccountsAPIDataSource which implements AccountsDataSource methods by calling AccountsAPI methods.
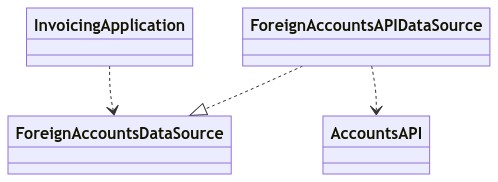
Notice how we are building our Foreign Accounts feature against a ForeignAccountsDataSource, which functions as a kind of contract between the InvoicingApplication (which we control) and the AccountsAPI (which the other team controls).
This contract helps us to think more clearly about what we need from the Accounts team - the inputs and outputs and behaviors. So we can communicate more clearly with the teams who we depend on about the data we depend on them for.
Sharing mocked states with team members
With mocked data in place, we can share various configurations of our application with team members such as QA engineers / testers, product owners, usability and accessibility professionals and others.
One technique applicable to web applications (which I used on a recent real-life project) is to configure the mock states via queryString parameters in the URL. The URL can then be shared with anyone who needs to see the web application in the mocked state. Rather than having the team member go through complicated sequences of steps to simulate a given state, all they need to do is to open the link.
For example, if we want to simulate the state in which the user entered a credit card into a payment page, but the card has expired, we might share a URL like this: http://myapp.com/payment-details?mockCreditCardExpired=true. This URL could be used to test the error message that is displayed for expired cards.
Other uses of mock data
We're talking about more than just simulating expected (or unexpected) application states! We can also simulate large data-sets (e.g. to test scalability), error conditions (to test error handling logic), delays (to test performance under various network conditions) and... well... anything else it's possible and useful to simulate. The ability to simulate specific application states is kind of a super power.
Summary
We've looked at four interrelated benefits of treating mock data with respect and rigour, with examples / pseudo-code for each.
- It helps us to clarify our software design by thinking about examples during modelling, before diving in to implementation.
- It boosts our unit testing efforts by providing a ready-made set of test inputs and making test code more readable and maintainable.
- It gives us the powerful capability to run our application independent of external data-sources and, as such, to simulate any application behavior we desire.
- Finally, it decouples us from immediate dependency on other teams while clarifying the relationships between teams by encouraging us to model them as contracts.
These benefits come at a cost. Using mock data in this way requires application code to be structured in a certain way (isolation of Application state). And it takes significant effort to augment a pre-existing application with mock data, especially if that application has complex logic.
Given all of the above, mock data seems best suited to long-term software projects of moderate complexity, where the advantages of using mock data outweigh the costs.
Related tools
- Mock Service Worker, targeted at web/typescript projects, provides some infrastructure for mocking web endpoints. The application can make requests as usual, but MSW can handle the requests and provide mock responses as if the Backend was mocked. The requests will appear in the Network Tab of Developer Tools, just like a regular request.
Further reading
Books that inspired me:
- Domain Modelling Made Functional • Scott WLASCHIN
- The Art of Unit Testing • Roy OSHEROV