TL;DR:To understand how a code-base is connected and functions at runtime, we can use execution flows. These map the paths through the code as it executes the code in real life. A rigorous format can map directly to the code-base, enabling an accurate depiction. An appropriate format can be fed into a tool such as Mermaid, to generate a visual flowchart.
Anyone who has spent some time developing software knows writing new code is but a small part of the job. At least as big, perhaps bigger, is understanding the existing code. And that includes understanding the runtime behaviour of that code!
I often found myself having to understand a complex cluster of code modules, entailing many function calls being made and many data types being passed and returned.
To properly understand the behaviour of the code, I needed to see a whole flow together at once so I could reason about it. I needed to somehow visualise it, e.g. by listing out the function calls in a text editor or maybe drawing a diagram on a piece of paper or in a diagramming application.
After doing this quite a few times, I have started to evolve a more consistent and powerful format, one which is text-based (and so, easy to work on in a standard text editor) but can also be converted to a visual flowchart using a tool called Mermaid.
In this article I want to describe this format and the reasoning behind it.
Execution flow notations can be useful in understanding an existing code-base, troubleshooting bugs, communicating with other team members and for solution design.
But first some background...
What is an execution flow?#
It's helpful to define the concept of "execution flow".
I'm referring to the path that the runtime will take through the code as it executes the code during a real-life use case.
You should not confuse this with a more specific term: call stack. Since a flow can include multiple function calls in sequence, each producing its own distinct call stack, a flow can include multiple call stacks. Much of the complexity of an execution flow is precisely that calling of multiple functions and the passing of data to them and returning of data from them. So "call stack" is too narrow a term to cover what I'm trying to describe.
On the other hand, you should also not confuse this with a more general term such as abstract syntax tree or "code structure". We are not describing the code as a whole, but just one path of possible execution of the code. Any piece of code that has one or more conditionals (e.g. if or switch statement, etc.) will execute differently depending on how those conditionals evaluate. For the same code, different lines might execute depending on the situation (e.g. depending on external state of some kind such as a database, web-service, system clock, etc.). Thus one code base can support multiple execution flows.
Example of an execution flow#
Let's use a hypothetical example – handling a user login on a Java backend.
class LoginResource {
...
private Response login(String username, String password) {
if (this.userAuthProvider.isValidUser(username, password)) {
this.sessionProvider.setCurrentUser(username);
return new Response(200, "Login succeeded.");
} else {
return new Response(401, "User credentials are invalid.");
}
}
}Can you spot the two execution flows in this code?
Flow 1 - Logging in successfully
First, we have flow when the user's credentials are valid.
Here's that code example again, with the relevant lines highlighted:
class LoginResource {
...
private Response login(String username, String password) {
if (this.userAuthProvider.isValidUser(username, password)) {
this.sessionProvider.setCurrentUser(username);
return new Response(200, "Login succeeded.");
} else {
return new Response(401, "User credentials are invalid.");
}
}
}- Inside
login(), theifcondition callsUserAuthProvider::checkUserCredentials, passing user credentials. UserAuthProvider::checkUserCredentialsreturnstrue.- Execution proceeds into the
thenblock. - We call
SessionProvider::setCurrentUser, passing user credentials. - We return
Response, passing success parameters.
Notice that this isn't just a single call-stack, as there are actually two method calls in this flow, each of which will generate its own call stack.
UserAuthProvider::checkUserCredentialsSessionProvider::setCurrentUser
Flow 2 - Failure to log in
What if the user credentials are not valid and isValidUser returns false?
That would be a separate execution flow.
Here's the code example once more, with the relevant lines highlighted:
class LoginResource {
...
private Response login(String username, String password) {
if (this.userAuthProvider.isValidUser(username, password)) {
this.sessionProvider.setCurrentUser(username);
return new Response(200, "Login succeeded.");
} else {
return new Response(401, "User credentials are invalid.");
}
}
}- Inside
login(), theifcondition callsUserAuthProvider::checkUserCredentials, passing user credentials. UserAuthProvider::checkUserCredentialsreturnsfalse.- Execution proceeds into the
elseblock. - We return
Response, passing failure parameters.
Tools for finding execution flow#
So how to we figure out how our code flows in the first place?
We can, of course, just read the code, open various files as needed, and try to follow along in our head.
Thankfully we also have automated tools to help reduce some of the tedium. You'll likely be familiar with these:
- Go to definition - we can select a reference (function, class, variable, etc) and be taken to its original definition
- Find references - we can select a definition (function, class, variable, etc) and pull up a list of all points in the codebase which reference the definition
Different IDEs name these differently, but most mainstream IDEs have them in one form or another, including IntelliJ IDEA, VSCode, Visual Studio and xCode.
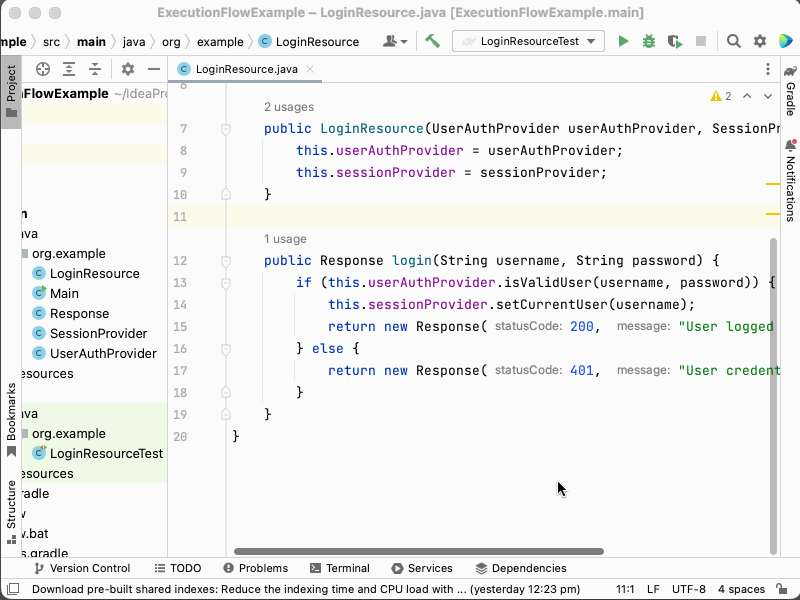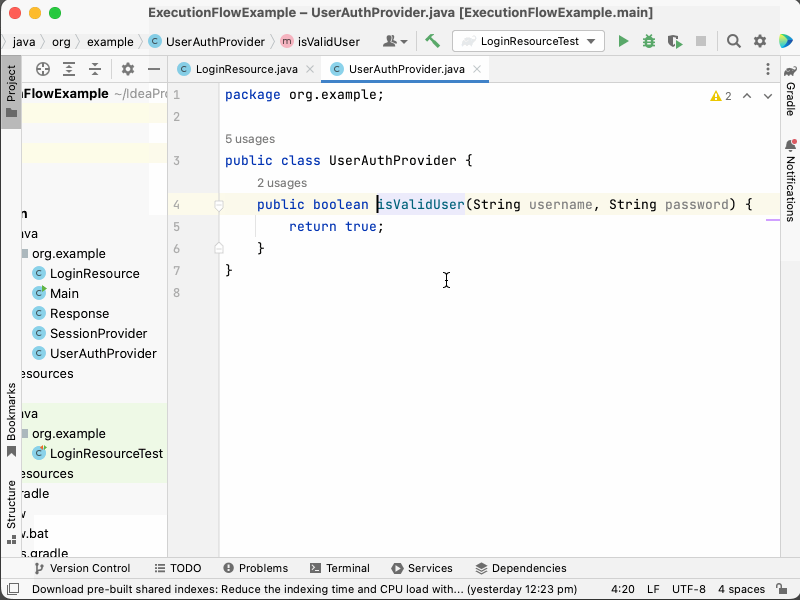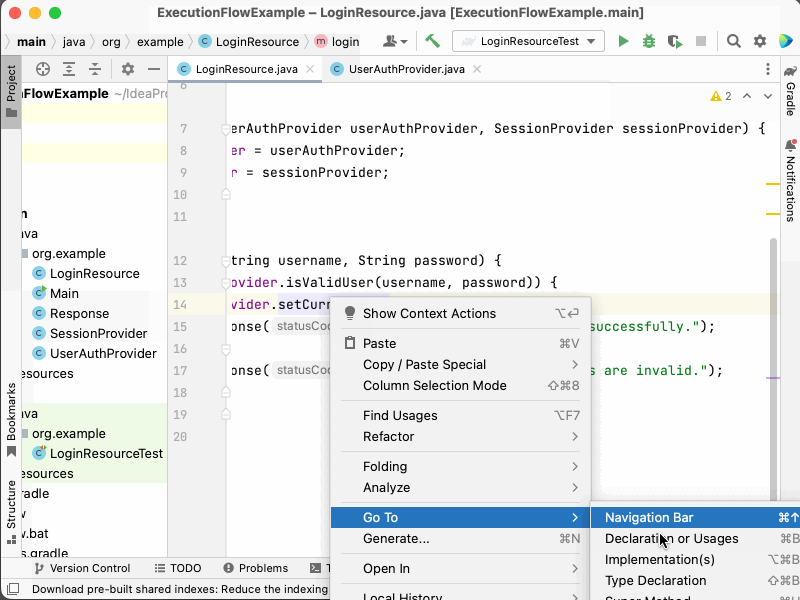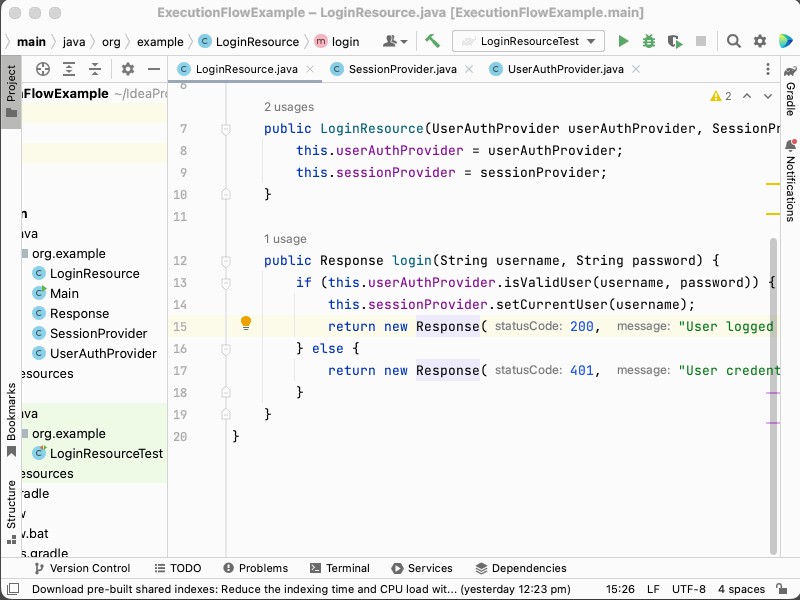
For example, in the code sample given previously, we might use Go to definition to locate the class whose login method is being called.
- Go to the
LoginResourceclass and itsloginmethod. - Right-click the
isValidUsercall and select "Go to definition". - Observe that it is defined in the
UserAuthProviderclass and itsisValidUsermethod. - Go back the
LoginResourceclass and itsloginmethod. - Right-click the
setCurrentUsercall and select "Go to definition". - Observe that it is defined in the
SessionProviderclass and itssetCurrentUsermethod. - Go back the
LoginResourceclass and itsloginmethod. - Observe that a new
Responseobject is constructed.
We might want to find out where else the UserAuthProvider::isValidUser method is called.
Supposing there was a RegisterResource class having a register method, as shown below:
class RegisterResource {
...
private Response register(String username, String password) {
if (this.userAuthProvider.isValidUser(username, password)) {
this.sessionProvider.setCurrentUser(username);
return new Response(200, "Login succeeded.");
} else {
this.userAuthProvider.registerUser(username, password);
}
}
}Then we might locate this piece of code by using the Find references tool:
- Go to the
UserAuthProviderclass and itsisValidUsermethod. - Right-click the
loginmethod and select "Find usages". - Observe that it is called in the
LoginResourceclass, in itsloginmethod. - Observe that it is also called in the
LoginResourceclass, in itsregistermethod. - Observe that a new
Responseobject is constructed.
Describing with text#
Suppose we wanted to make some notes of the execution flows we discovered. Maybe there are too many for us to easily memorise. Perhaps we want to see them all in one view rather than scattered among many files.
Let's start with the first flow – successful login:
flowchart
LoginResource::login
--->|userName,password| UserAuthProvider::isValidUser
---|true| LoginResource::login
--->|userName,password| SessionProvider::setCurrentUser
--- LoginResource::login
--->|200,'Login succeeded.'| Response::constructorThen the second flow – successful login:
flowchart
LoginResource::login
--->|userName,password| UserAuthProvider::isValidUser
---|false| LoginResource::login
--->|401,'Login failed. Invalid credentials.'| Response::constructorAnd the final flow – register:
flowchart
LoginResource::register
--->|userName,password| UserAuthProvider::isValidUser
---|true| LoginResource::register
--->|200,'Login succeeded.'| Response::constructorNow we can step back and look at all these flows together and see the bigger picture, e.g. how login and register both check user validity using UserAuthProvider, and how both instantiate the Response class with various constructor parameters.
Notation#
Did you notice the textual format used in the previous section to notate the execution flows?
Let's deep-dive into that.
flowchart
Class::methodCalling
--->|parameters| Class::methodBeingCalled
---|return values| Class::methodCallingClass::methodCalling- the caller--->|parameters|- execution flowing from caller to callee, with the parameters being passed in the callClass::methodBeingCalled- the callee---|return values|- execution flowing from callee back to caller, the value returned from the calleeClass::methodCalling- the caller (again)
We can chain these together to notate a sequence of consecutive calls.
For example:
flowchart
Class1::method
--->|parameters| Class2::method
--->|parameters| Class3::method
---|return values| Class2::method
---|return values| Class1::methodClosures and indirection#
Thusfar we've use the Class::method format to reference the callers and callees. This should work reasonably well for classical OO code-bases written in Java, C#, Swift etc.
But what if we want to reference code in other ways, such as named closures, for languages written in Javascript, Typescript, etc.?
Here are some notations that could allow such structures to be referenced:
Nested closure
foo/bar - Reference a closure witin another closure.
Indirect call
-.-> - References an indirect method call - a call which our code doesn't make directly, but causes to be made, such as calling setTimeout on a function in Javascript. It looks like a dotted line.
Example in Javascript
Let's use an example – a recursive Javascript function – to put all these ideas together.
function retry(action, times, count = 1) {
const timeout = Math.pow(count, 2) * 1000;
setTimeout(function handleTimeout() {
if (!action() && count <= times) {
retry(action, times, count + 1);
}
}, timeout);
}retry is a recursive function, which calls setTimeout, passing a closure. That closure executes. Depending on the number of times retry has called itself already (time), it may call retry again or simply do nothing, halting the recursion.
We can notate this execution flow, including the closure, using the nested closure, multiple calls, row/column and indirect call notations given above, in the following manner:
flowchart
retry
-.->|action, times=3| retry/handleTimeout
---> action
---|false| retry/handleTimeout
--->|action, times=3, 2| retry
-.->|action, times=3, count=2| retry/handleTimeout
---> action
---|true| retry/handleTimeout
---retryVisualising with Mermaid#
Now the juicy part – lets look at how this format can be instantly converted into a visual flowchat using Mermaid!
Mermaid is a free, open-source tool, which takes code written in a specific syntax and converts it into a diagram.
You can run Mermaid in the browser using Mermaid Live, or if you prefer, you can download and run it locally using the instructions on the mermaid-live-editor GitHub profile.
We'll need to add the keyword graph to the top of the text.
Also, in these examples, we add numbered circular nodes (e.g. ---n1((1))) to indicate the order of execution.
The following is how our two earlier Java examples – login success and login failure – render in Mermaid:


And here's the Javascript example:

Notice that we've added small numbered circles, indicating the order in which the calls occur. This makes the flow a bit easier to navigate.
Imagine this appearing in a Slack conversation:
It could potentially be easier to read and follow an execution flow diagram than to read paragraphs of text trying to describe in plain language the complex sequence of calls.
Isn't this just a flowchart?#
Yes, but it's a specialised form of flowchart, focussed on representing execution flow.
The flowchart directly maps to the code it represents, so it accurately and unambiguously conveys information about that code. At the same time, because it's not actually code, but a diagram, it allows us to more easily view and reason about the code in terms of execution flows specifically. We don't have to jump around between files, scroll up and down, etc. but can see a whole execution flow in one screen.
Also by establishing and adhering to a convention in how we represent callers, callees, parameters and return values, etc. this flowchart technique is re-usable across programming languages, codebases, business domains, etc. A similar versatility is found in UML, sequence diagrams and other kinds of specialised diagram formats.
Sequence diagrams#
You might have seen diagrams similar to those described here, but laid out as sequence diagrams. Execution flows can certainly be visualised as sequence diagrams. A sequence diagram is arranged as a set of vertical columns connected by arrows, where each column represents a method and each arrow represents a call.
There are weaknesses of sequence diagrams, however.
- They present each method in a column, so we may soon run out of horizontal space, whereas flowcharts can flow down and across. Also, even for lengthy flowcharts, scrolling up and down is easier on most devices than scrolling side-ways.
- They may position the caller and the callee very far apart, so that the eye has to scan back and forth over a large distance to see the call, whereas flowcharts can more position the caller and callee closer together, making scanning easier.
For these reasons, I find the flowchart format more appealing.
Automatic generation#
Surprisingly, not really.
For dependency visualisation, I found a few interesting plugins for VSCode, and also experimented with IDEA's dependencies analysis tool.
However, all of these tools are focused on reporting compile-time dependencies, which are a different kind of thing to execution flows.
Dependency graphs of course help us to understand how code is structured, but they don't give us the full picture of which parts of that code execute in which order at runtime. For that, we really need execution flows.
Theoretically any tool that could automatically report execution flows would need to be able to analyse the code in terms of its expected execution at runtime. The tool might, like a debugger, execute the code, in order to determine the flow of control, e.g. where the flow of control depends on some state which can only be discovered at runtime. Or it could statically analyse the code to determine all possible flows and generate a report of all of them.
It's beyond the scope of this article to look into how such a tool could be developed, but it's something I'm interested in looking into and perhaps even undertaking myself.
Conclusion#
This article has outlined a format for describing execution flow, which can be used to visualise and understand how parts of a codebase execute at runtime (and generate diagrams).
This understanding can help to diagnose bugs/errors, determine the best points at which to change the code, estimate how long changes might take, and no doubt many other use cases.
I hope you find it useful!
Further reading#
These books inspired this article:
- The Pocket Guide to Debugging • Julia EVANS
- UML Distilled • Martin FOWLER
